
Ensemble Models - the next wave of neural nets?
Trends in Imagenet ILSVRC solutions and what they mean for AI
What is Imagenet ILSVRC?
I'd be remise to explain what ILSVRC is without first touching base on what Imagenet itself is. Imagenet is a machine learning dataset popular among researchers and academics, particuarly within the computer vision sub-sector of computer science.
Imagenet provides a set of images for each synset of WordNet which is, in turn, another popular machine learning dataset.
Each year, the best computer vision research teams from around the world compete in the Imagenet Large Scale Visual Recognition Challenge (or ILSVRC), and submit solutions against a number of different challenges, which differ slightly each year to ensure new solutions are submitted.
ILSVRC is without a shadow of a doubt the world's most prestigious computer vision competition. Successful solutions can provide insight into which algorithms will be heavily researched and commercialised in coming years. Alex Krizhevsky’s ILSVRC deep convolutional neural net based 2012 winning entry, for example, achieved an error rate of 15.315%, compared to the closest competitor at 26.172% using a weighted sum of scores from classifiers such as SIFT and CSIFT. [WHAT DID HE USE?]. The rise in popularity of deep learning algorithms applied to computer vision can be partially attributed to Krizhevsky’s feat.
Why is this interesting?
Well, many would argue that is it not. However the fact you got this far tells me you're likely either a software engineer or computer scientist, or you're interested in fringe technologies such as cognitive computing for other reasons. As mentioned earlier, the best computer vision research teams compete in this competition annually. As the industry often adopts the most interesting or commercially valuable findings from academic research, ILSVRC solutions can provide a useful guidance as to where the computer vision industry is heading.
The Challenges - 2016
Object localization for 1000 categories.
Object detection for 200 fully labeled categories.
Object detection from video for 30 fully labeled categories.
Scene classification for 365 scene categories (Joint with MIT Places team) on Places2 Database http://places2.csail.mit.edu.
Scene parsingNew for 150 stuff and discrete object categories (Joint with MIT Places team).
The Trends
The most interesting thing that comes out of ILSVRC each year, at least for me, are people's interpretations of the results and what they mean for the computer vision sector.
What I'm weary of is that many people tend to pluck a particular methodology or approach from the results table without really understanding:
- What the approach and related terminology actually means,
- What the underlying influences are for the distribution of certain techniques.
One example of this may be the seemingly prominent use of ensemble models. At first glance of the ILSVRC 2016 results one would think that ensemble models were a new innovation within computer vision. Let's take a look at the numbers behind ensemble models and their use in ILSVRC in 2014.
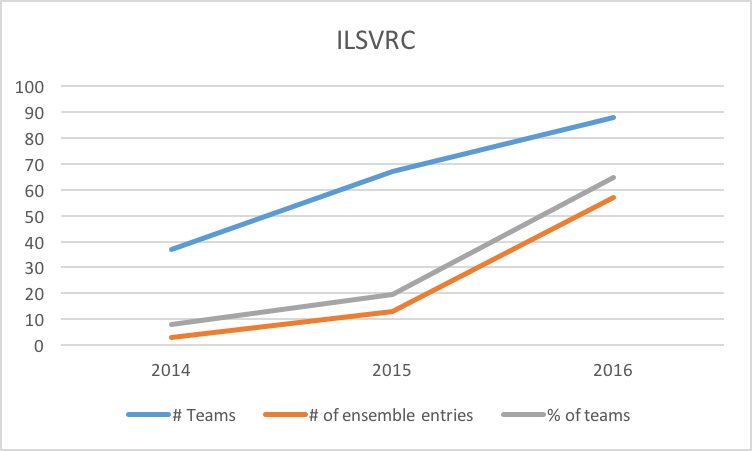
The graph above shows three data series, the number of teams participating, the number of ensemble entries, and the percentage of teams who utilised ensemble model approaches to the challenges at least once in the competition. The latter two series only show data for solutions that explicitly claim the use of ensemble models in their solutions, and omits the use of solutions that are likely ensemble implementations (for example, "multi-network solutions") as this could not be validated. The graph takes into account the number of teams, and ignores any other than the first solution submitted by a team making use of ensemble models. As you can see, there is a clear trend toward the use of ensemble models within the ILSVRC competition from 2014 to now, with the number growing from ~8% to ~66%.
What is an ensemble model?
Ensemble models, and ensemble learning, the method used to produce such models, can be thought of simply as the combination, or ensembling of models. There are a number of types of ensemble models and methods, with some of the most common being:
- Bootstrap Aggregating (Bagging)
- Boosting
- Stacking
- Voting Ensembles
You likely come across such models often in every day life. For example, the Netflix recommendation engine is not a single model, but an ensemble of models trained to react to different behaviour, such as viewing history, ratings, click-throughs etc.

Think of an ensemble algorithm like a barber shop quartet (or in the case of the image above, a quintet). Each singer in the quartet might individually have a very questionable voice, however when these voices are combined in the right way, with different volumes for each,they produce a pleasing melody.
Ensemble models are much the same, where each model within the ensemble receives a weight, much like the volume applied to a member of the quartet, and the combined and weighted result of the ensemble produces a better result than that of any one individual model within the ensemble.
So if Ensembles were outperforming single mode solutions in 2014, why did it take until 2016 for them to reach critical mass in ILSVRC?
While I may only speculate, I believe this comes down to the enormous hardware requirements of training and testing ensemble models. Many companies struggle to analyse single gigabytes of data within neural nets or deep learning.
The teams submitting solutions within ILSVRC face this same problem, but often with orders of magnitude more data. If you look at the fact that even the dataset for a single challenge, the scene parsing challenge is well over 400 giagbytes of visual data, in which each and every frame must be analysed (well over 10 million of them), you'll start to gain an understanding of just how complex these training operations are. Given that most teams will also train on their own private datasets, and will train a single model dozens of times whilst tweaking hyper-parameters, this really is a mammoth task. Now imagine performing this training, however instead of a dozen or so layers deep like the models you likely train, some of the models submitted are over 100 layers deep, and in an ensemble model there may be several separate models to be trained individually prior to the production of the ensemble solution.
If we now take this understanding, and look at the teams who submitted ensemble model based solutions in 2013, this starts to make alot of sense. Two of the three teams providing solutions including ensemble models in 2013 were:
*KAIST - A Korean university with a close relationship to Samsung Electronics - in fact providing ~25% of Samsung's R&D PHDs
*Google with their Googlenet team.
Both of these teams presumably have access to astonishing resources, and the growth of popularity of implementation speaks verses for the democratisation of powerful infrastructure as a service such as the GPU hosts offered and continuously improved by players such as Amazon in the cloud computing space. Access to such platforms provides teams the ability to scale their solutions up to datacenter scale without the need to invest in private datacenter racks that may not see adequate utilisation throughout the rest of the year.
Ensemble models prior to deep learning
Interestingly, if we revert to the 2012 ILSVRC in which Alex Krizhevsky blitzed the competition with his deeply convolutional neural nets, the second placed competitor used a weighted sum of more traditional classifiers such as the scale invariant feature transform. This is, in essence, and ensemble model - as was the third placed solution.
What this tells us is that the surge in popularity of convolutional neural nets (CNNs) cannibalised the popularity of ensemble models, due to the huge computational power required to produce CNNs. As GPU based IaaS was democratised further, ensemble models once again became viable as people gained access to the amount of computing power required to produce and combine multiple CNNs.
Are ensemble models the next wave or neural network implementations?
Yes and no. I don't think the use of ensemble models is so much the next wave as it is the next logical step in how to improve these models with access to the same datasets and more powerful, readily accessible hardware. Ensemble learning allows computer scientists to train models that excel at specific things, such as the singer in the barber shop quarter who can only sing in a very deep tone, whilst also capturing the other octaves in the verse, so to speak
The democratisation of parallel computing architectures via GPU hosts available by the minute on the public cloud allows machine learning and computer vision companies and scientist to leverage techniques previously inaccessible, and I think as a result we'll see a lot more ensemble models being developed and deployed for various problems.
This post, whilst based mainly on fact, is an opinion piece. Do you agree with me? Why not? Let me know in the comments below, I'd love to hear your take on this year's ILSVRC results, or the trends and future of computer vision and machine learning in general!
TLDR;
CTO Nova Eye Medical, building current and future generation devices to treat the world's leading causes of blindness. Background in Artificial Intelligence and Capital Markets, Lover of Business, Technology and Markets